




Read more
UNIT 2
Introducing to
Database and Database Management System
Concept
of Data
In today’s world, it
is said that information is power. Due to the rapid change of information
technology, we have realized that the value of information, as a source. The importance
of the speed and ease of which this resource can be managed is equally
important to us. The term database literally means it is the basis of data.
Data can be defined
as a set of isolated and unrelated raw facts, represented by values which have
little meaning. Data are raw facts. The word 'raw' is used to indicate that the
facts have not yet been processed to reveal their meaning. Data are information
to the computer that is to be processed to get a relevant result. Processed
results are called information.
Data has some key
points to understand. These key points of data are:
1.
Data constitute the building blocks of information.
2.
Information is produced by processing data.
3.
Information is used to reveal the meaning of data.
4.
Good relevant and timely information are the key to good
decision making.
5.
Good decision making is the key to organizational survival in a
global environment.
It is clear that
timely and useful information requires good data. Such data must be generated
properly and stored properly in a format that is easy to access and process.
Data management is a discipline that focuses on the proper generation, storage
and retrieval of data.
Data management is
the core activity for any business, government organization, service
organization or charity. Efficient data management requires the use of computer
database. Information can be defined as a set of organized and validated
collection of data. Knowledge is the act of understanding the context in which
the information is used. It can be based on learning through information,
experience, guessing intuition, etc. Based on the knowledge, information can be
used in a particular text.
Thus, the term data
processing means the process of collecting all items of data together to
produce meaningful information. It can be done either manually or by the use of
computers. If data processing is done with the help of computers, it is known
as EDP (Electronic Data Processing).
Hence, the
information that we obtain after processing the data must possess the following
characteristics.
1.
It must be accurate.
2.
It must be available in time as required.
3.
It must be complete so that more inference can be drawn.
4.
It should be precise in meaning.
5.
It should be relevant to the context.
Database
A database is an
organized collection of data in an easily accessible form which is shared and
used for multiple purposes. In our day to day life, we come across several
databases.
·
In our home, we take care of our personal business with some database
of a check book, phone book, address book, etc.
·
In our offices, we keep information about our clients, their
phone numbers, etc.
·
We keep detailed information of our employees, their salary,
their job description, etc.
·
In school, we keep the records of students, their name, address,
parents’ name, etc.
·
Government agencies keep the records of the census.
A database contains
records and fields. A record is a collection of different types of information
about the same subject. In the case of the telephone book, the category address
is a field.
In broader sense, a
database is shared, integrated computer structure that houses a collection of:
1.
End user data i.e. raw facts of interest to the end user.
2.
Metadata or data about data through which the data are
integrated.
Database Name: EMPLOYEE
EMP_ID | EMP-NAME | ADDRESS | TELEPHONE | SALARY |
A4002 | YUNIF | PATAN | 977552345 | 12000 |
Functions
of Database
In a general file
processing system, records are stored permanently in various files. There are
numerous application programs which can extract records and add the records to
the appropriate files. These processes have many advantages and disadvantages.
They cannot provide data redundancy (duplication of data) and other facilities.
The functions of
database are:
1.
To store, manipulate and manage the information.
2.
To reduce the repeated storage of the data (data redundancy) and
improve the disk optimization.
3.
To keep latest and correct information (Data Consistency).
4.
To automate the data managing and processing system.
5.
To provide data validation facilities.
6.
To improve data security system.
Fundamentals
of Database
Let ustake the example of the following table
of some students. This reflects the database concept that based on data
processing systems.
Roll No. | Name | English | Nepali | Science | Math | S. Std. | Total |
1. | Susmita | 78 | 56 | 78 | 90 | 90 | 392 |
2. | Kamal | 67 | 78 | 90 | 91 | 89 | 415 |
3. | Amrit | 56 | 45 | 55 | 78 | 80 | 314 |
4. | Aakash | 67 | 78 | 85 | 90 | 90 | 410 |
5. | Shasank | 78 | 56 | 80 | 90 | 70 | 374 |
The above table
contains cells. Each cell comprises of the outer border. The border thus formed
has made a grid of cells. The combination of these cells is called Table.
Table: The database in
Relational Database Management System (RDBMS) like MS-Access is in table form.
There are many tables that you can create in a database. Each table has at
least a primary key. The relation between these tables can be established with
the following concept.
1.
One to one: Relation between two primary keys of the two tables.
2.
One to many: Relation between primary key and non-primary key of
the two related tables.
3.
Many to many: A link table between two tables can create many to
many relations with the help of primary key and non-primary keys.
Field: A field is a piece of
information about an element. A field is represented by a column. Every field
has got a title called the field title.
Record: A record is an
information about an element such as a person, student, an employee, client,
etc. A record can have much information in different heading or titles.
Basic
Terms of Database
Some important
database-related terms are as follows:
·
Data Type: A data type determines the type of data that
can be stored in a column (field). The most common data types used in databases
are Alphanumeric, Boolean and Data and time.
·
Key: A key or key field is a column value in the table that is
used to either uniquely identify a row of data in a table or establish a
relationship with another table. The keys can be of three types. They are
Primary key, Foreign key and Candidate key.
·
Data Dictionary: The data dictionary defines the basic
organization of a database. It contains the list of all files in the database,
the number of records in each file and the names and types of each field.
Database
Management System (DBMS)
Database Management
System is a software that manages the data stored in a database. This is a
collection of software which is used to store data, records, process them and
obtain desired information. Since, data are very important to the end users, we
must have a good way of managing data.
The DBMS contains a
query language that makes it possible to produce a quick answer to ad-hoc
queries. A query is a question and an ad-hoc query is a spur of the moment
question.
fig. DBMS
The DBMS helps create
an environment in which end users have better access to more and better-managed
data than they did before the DBMS become the data management standard. Such
access makes it possible for end users to respond quickly to the changes in
their environment.
A DBMS is a
collection of programs that manages the database structure and controls access
to the data stored in the database. The DBMS make it possible to share the data
in the database among multiple applications or users. The DBMS stands between
the database and the user.
Features
of Traditional Database System:
The most common
database management systems used in early time were DB2, DBASEIII, DBASEIII+,
FOXPRO, etc. The applications were developed independently for different
departments and organizations and files of information relevant to one
particular department were created and processed by dozens or even hundreds of
separate programs.
The features of
traditional database management system are:
1.
Data redundancy: The data of a single record was present in a
different place in different form and it was repeated in many ways.
2.
Data inconsistency: When data in a file is changed it did
not support other database or files.
3.
Program –Data Dependence: The data were merely
dependent on the program. Any change in the structure of database led to damage
of data.
4.
Data was not shareable: Data in different computers were
personalized. They were not accessible from other computers and users.
5.
Data integrity: The database integrity was not maintained.
INTRODUCTION
TO DATABASE MODELS
The quest for better
data management has led to several different ways of solving the file system’s
critical shortcomings. The resulting theoretical database constructs are
represented by various database models.
A database model is a
collection of logical constructs used to represent the data structure and the
data relationships found within the database.
Database models can
be grouped into two categories:
1.
Conceptual Model
2.
Implementation Model
Conceptual
Model
The conceptual models
use three types of relationships to describe associations among data:
1.
One-to-many relationship: A painter paints many
different paintings, but each one of them is painted by only that painter.
2.
Many-to-many relationship: An employee might
learn many job skills, and each job skill might be many employees.
3.
One-to-one relationship: A retail company’s
management structure may require that each one of its stores is managed by a
single employee. In turn, each store manager who is an employee only manages a
single store. Therefore, the relationship is one to one.
Implementation
Model
An implementation
model places the emphasis on how the data are represented in the database or on
how the data structures are implanted to represent what is modeled.
Implementation models include:
i.)Hierarchical-Database-Model
ii.)Network-Database-Model
iii.)Relational-Database-Model-and
iv.) Entity Relationship Database Model
i.)
Hierarchical Database Model
North American
Rockwell was the prime contractor for the Apollo project, which culminated in a
moon landing in 1969. Bringing such a complex project to a successful
conclusion, this process requires the management of millions of parts.
Information concerning the part was generated by a complex computer file
system.

When North America
Rockwell began to develop its own database system, an audit of computer tapes
revealed that over 60% of the data were redundant (repeated). The problems
caused by data redundancy forced North American Rockwell to develop an
alternate strategy for managing such huge data quantities.
Borrowing parts of
existing database concepts, they developed software known as GUAM (Generalized
Update Access Method), which was based on the recognition that the many smaller
parts would come together as components of still larger components and so on
until all the components came together in the final unit.
In the mid-sixties,
IBM joined North American Rockwell to expand the capabilities of GUAM replacing
the computer tape medium with more up-to-date disk computer storage which
allows the introduction of complex pointer system. The results of the joint
Rockwell-IBM effort become known as the Information Management System (IMS).
Advantages:
1.
The relationship between various layers is logically simple.
2.
This system provides a tough database security.
3.
Hierarchical database system maintains data independence i.e. if
a data is altered in one table, it does not affect the other location.
4.
There is always a parent-child relationship and data integrity
is maintained.
5.
For a large volume of data and 1:M relationship, it is a very
efficient model.
Disadvantages:
1.
The physical implementation of the database is complicated.
2.
Alternation in database structure is difficult to manage.
3.
Structural independence exists when changes in the database
structure do not affect the DBMS’.
4.
Application programming use complexity which may exist in many
cases.
5.
Implementation limitations due to the incapability of managing
the relation such as M:N.
6.
It lacks in DDL and DML standard of commands.
ii.)
Network Database Model
Network database
model was created to represent complex data relationships more effectively than
the hierarchical model, which could improve database performance and impose a
database standard. The lack of database standards was troublesome to
programmers and application designers because it made database designs and
applications are less portable.
In many aspects, the
network database model resembles the hierarchical database model. It also uses
the same principle of 1:M relationship. However, quite unlike the hierarchical
model, the network model allows a record to have more than one parent.
Therefore, the commonly encountered relationships can be handled easily by the
network database model.

Using network
database terminology, a relationship is called a set. Each set is compared to
at least two record types: an owner record that is equivalent to the hierarchical
model’s parent and a member record that is equivalent to the hierarchical
model’s child. A set represents a 1:M relationship between the owner and the
member.
Advantages:
1.
The database is conceptually simple in structure.
2.
It can handle more relationship types.
3.
It has data access flexibility such as accessing its own record
and all the member records in the set.
4.
Promotes database integrity since owner record and member
records are defined precisely.
5.
Changes in the data integrity since owner record and member
records are defined precisely.
6.
Changes in the data do not require a change in access methods
which is the benefit of data independence.
7.
It confirms the standards such as DDL (Data Definition Language)
and DML.
Disadvantages:
1.
Since, the system is complex the system navigators, database
administrators, programmer and end users must be very familiar with the
internal structure in order to access the database. Lack of structural
independence
2.
Although, the network mode achieves data independence, it still
does not produce structural independence.
iii.)
Relational Database Model
The Relational Model,
first developed by E.F. Cod (of IBM) in 1970, represented a major breakthrough
for both users and designers. To use an analogy, the relational model produced
an “automatic transmission” database to replace the “standard transmission”
database that preceded it.
Its conceptual
simplicity set the stage for a genuine database revolution. Codd’s work was
considered ingenious but impractical in 1970. The relational model’s conceptual
simplicity was brought at the expense of computer overhead; computers lacked
the power to implement the relational model.
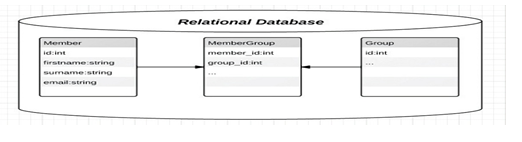
The relational
database model is implemented through a very sophisticated relational database
management system (RDBMS). The RDBMS performs the same basic functions provided
by the hierarchical and network DBMS system plus a host of other functions that
make the relational database model easier to understand and to implement.
Advantages:
1.
Data access paths are irrelevant to relational database
designers, programmers and end users. It is possible to change database
structure without changing the method of accessing data.
2.
This model is simpler and possesses improved conceptual
simplicity.
3.
It provides easier database design, implementation, management
and use.
4.
It possesses ad-hoc query capabilities.
5.
It possesses a powerful database management system.
Disadvantages:
1.
Substantial hardware and system software overhead due to the
complex structure of database hidden procedures within the system.
2.
In microcomputer based systems, it has a poor design and
implementation is made easy.
3.
Many promote “islands of information” problems since some
database are isolated from other locations or system complexity.
iv.)
Entity Relationship Database Model
The relational
database model’s conceptual simplicity made it possible to expand the
database’s scope. Therefore, the introduction of relational database technology
triggered a demand for more and increasingly complex transactions and information.
In turn, the rapidly
increasing transaction and information requirement created the need for more
complex database implementation structures, thus, creating the need for more
effective database design tools.

Complex design
activities requires conceptual simplicity to yield successful results. Although
the relational database model was a vast conceptual improvement over the
hierarchical and network database models, it still lacked the features that
which might make it an effective database design tool because it is easier to
examine structures graphically than to describe them in text form. Database
designers find it desirable to use a graphical tool in which entities and their
relationships can be pictured.
Advantages
1.
It yields a particularly easily viewed and understood conceptual
view of a database’s main entities and their relationships.
2.
The ERM gives the designers visual representation very clearly.
3.
The ERM has become one of significant effective communication
tools in RDBMS.
4.
The ERM is well integrated with the relational database model.
Disadvantages
1.
Limited constraint representation due to limited model.
2.
The relationship between attributes within entities cannot be
represented. Example, there is no way of completed hours and classification of
a student.
3.
It lacks in data manipulation language or commands.
4.
The models becomes crowded due to more presence of entities.
Normalization
Normalization
of Data
Normalization is a
process which has a setof steps that enables to identify the existence of
potential problems called update anomalies (irregularities) in the design of a
relation database. This process supplies the methods for correcting these
anomalies. In this process, it involves converting tables into various types of
normal forms. A table in particular normal form processes a certain desirable
collection of properties.
The normal forms are
1NF, 2NF,3NF, which were later extended by Boyce-Codd. The normalization
process allows a table or collection of tables and produces a new collection of
tables that represent the same information but free of anomalies.
In the normalization
process, two terms are basically used. They are functional dependence and keys.
Functional
dependence:
Functional Dependence
is a formal name for what is basically a simple idea. Example: A sales
representative pay class determine his or her commission rate. In other words,
a sales representative’s pay class functionally determines his commission rate
or a sales commission rate functionally depends on his pay class.
File name: SaleRep
Sales Rep | Last Name | First Name | Price | City | Commission | Rate |
[Note: Each blank row
can hold data]
Filename: Customer
Customer Number | Last Name | First Name | Place | City | Balance | Credit Limit | Sales rep number |
[Note: Each blank row
can hold data]
A column (attribute)
B is functionally dependent on another column (or possibly a collection of
columns), if a value for A determines a single value for B at any one time. The
functional dependence of A is written as (AàB). If B is functionally dependent
on A. This can express as A functionally determines B.
Functional dependence
is determined on the basis of the unique field. For example, last name,
address, ID code, etc.
Keys
It is the second
underlying concept of the normalization process. A primary key is very
important. A column (attribute) C (or collection of columns) is the primary key
for table (relation) T.
If;
1.
All column in T is functionally dependent on C.
2.
No sub-collection of the columns in C (assuming C is a
collection of columns and not just a single column) also has property (a).
Example, given the
name, you cannot determine the address, city etc. In this case, you will choose
candidate key. The candidate key is a column or collection of columns on which
all columns in the table are functionally dependent. The primary key defines
the candidate key as well.
The candidate keys
that are not chosen to be the primary key are often referred to as an alternate
key. The primary key is frequently called simply, the key in other studies on
database management and the relational model.
First
Normal Form
A table (relation) is
said to be the first normal form ( 1NF) if it does not contain the repeating
groups. A table (relation) that contains a repeating group (or multiple entries
for as single record) is called a non normalized relation. Removal of repeating
groups is the starting points in the quest for tables that are free of problems
as possible.
Tables without repeating
groups are in the first normal form. In the given table, if a student (SIDà
100) is deleted, the information about the fee of Golf is lost. This has
deletion anomaly. Similarly, if a student wants to take part in cricket, its
fee is unknown. It also possesses the insertion anomaly.
Second
Normal Form
Consider the third
relation in the above figure. Here, we have assumed that the student is allowed
to enroll for more than that one activity at a time. We observe that it has
modification anomalies. If we delete the tuple for student 175 (SIDà175), we
lose the fact that the monthly fee of squash is Rs. 50. Also, we cannot enter
an activity until a student signs up for it. Thus, the relation suffers from
both insertion and deletion anomalies.
The problem with this
relation is that it has a dependency involving only part of the key. The key
here is the combination (SID, Activity) but the relation contains dependency,
Activity a Fee (Fee depends on the type of Activity). The determinant of this
dependency (Activity) is only part of the key (SID, Activity). The modification
anomalies could be eliminated if the non-key attribute (Fee) were dependent on
all the key, not just a part of it.
To resolve the
situation, we must separate the relation into small ones. The situation now
leads to the definition of the second normal form:
A relation is in
second normal form if all the non-key attributes are dependent on the entire
key. Observe that this definition pertains to relations that have composite
keys. If the key is a single attribute, then the relation is automatically in
second normal form.
Filename: ACTIVITY
(SID, Activity, Fee)
Key: (SID, Activity)
Activities can be
split to form two relations in second normal form. The relations are the same
as those in fig.
STU-ACT
SID | Activity |
100 | Skiing |
150 | Swimming |
175 | Squash |
200 | Swimming |
ACT-COST
Activity | Fee |
Skiing | 200 |
Swimming | 50 |
Squash | 50 |
Third
Normal Form
The relation in
second normal form also has anomalies. Consider the relation HOUSING in given
fig. Here, the students stay in different houses and their cost prices per
quarter are different. The key here is SID and the functional dependencies are
SID à Building and Building à Fee (SID à Activity and Activity à Fee, as in
second normal form). The dependencies arise because a given student lives in
only one building and each building has its own fixed fee structure, for e.g.
everyone living in Yellow House pays Rs. 1200 per quarter.
Since, SID determines
Building and since, Building determines Fee, then, transitively SID à Fee.
Hence, SID depends on fee which is incorrect. Thus, SID, a single attribute, is
the key and the relation must, therefore, be in second normal form. The
relation, however, does still have anomalies. These anomalies can be resolved
by splitting the table.
HOUSING ( SID,
Building, Fee)
Functional
dependencies: Building à Fee
SID à Building à Fee SID à Housing
(SID,Building) BLDG-FEE (Building, Fee)
SID | Building | Fee |
100 | Yellow | 1200 |
150 | Blue | 1100 |
200 | Red | 1200 |
250 | White | 1100 |
300 | Green | 1200 |
Table 1 | ||
SID | Building |
100 | Yellow |
150 | Blue |
200 | Red |
250 | White |
300 | Yellow |
Table 2 | |
Building | Fee |
Yellow | 1200 |
Blue | 1100 |
White | 1100 |
Table 3 | |
If we delete the
second row of the Housing relation (table 1), we lose not only the fact that
student 150 lives in Blue house, but also that it costs Rs. 1100 to live there.
This is a deletion anomaly. Further, how can one record the fact that the fee
for XY House (imagine) is R.s 1500? We cannot do that until a student moves
into the XY House. This is an insertion anomaly. To eliminate the anomalies
from the relation in second normal, the transitive dependency must be removed.
This leads is to the definition of the third normal form:
A relation is in
third normal form if it is in second normal form and has no transitive
dependencies.
Housing relation in
above fig can be split into two relations in third normal form. The relation
STU-Housing (SID, Building) and BLDG-Fee (Building, Fee) are examples.
Structured
Query Language (SQL)
SQL was developed by
IBM in the, 1970s as a way to get information into and out of relational
database management systems. It was first standardized in 1986 ANSI. It is
declarative in nature. That is its commands are accurate and declared so that
they perform on particular databases. SQL commands are categorized as:
·
DDL such as create a table, alter table, drop table, etc.
·
DML such as select, insert into, update, delete from, etc.
SQL is a declarative
language. It is used to find the results of the database. SQL queries are the
most common in use. The SQL sublanguage DML and DDL are very common in
server-based database management system. For using SQL, you need to create the
table, insert data records into the table and then, you can manipulate the data
records or make the queries. A typical command could be:
SELECT CarModel FROM
CarSales WHERE CarSoldDate Between ‘May 1, 2005’ AND May 31, 2005’;
For creating database
you would like to enter the SQL command as:
CREATE TABLE MyFirstTable
(Stud_name varchar (40), Stud_Address varchar (40), Stud_Date Of Birth Date, ) |
For listing all the
records from the table, you would enter the command as:
Select * from My First
Table
Similarly, for various activities such as
deleting records, indexing records, filtering records, joining tables, etc.,
you have commands of SQL. These commands are beyond context at this level.
Database System
Environment and Data Security
Database
System Environment
The term database
system refers to the components of an organization that defines and regulate
the collection, storage, management and use of data within a database
environment. From a general management point of view, the database system is
composed of the five major parts:

1.
Hardware: The computer
2.
Software: The operating system, the utilities, the
files, file management programs and application programs that generate reports
from the data stored in the files
3.
People: Data processing managers, Data processing
specialists, programmers and end users
4.
Procedures: The instructions and rules that govern the
design and use of the software component
5.
Data: The collection of facts
Types of
Database Systems
A database system
gives us a way of gathering together specific pieces of relevant information.
It also provides a way to store and maintain that information in a central
place. A database system consists of two parts:
·
The Database Management System (DBMS) which is the program that
organizes and maintains these lists of information, and
·
The Database Application, a program that lets us retrieve, view,
and update the information stored by the DBMS.
The DBMS on which the
database system is based, can be classified according to the number of users,
the database site locations and the expected type and extent of use.
The numbers of users
determine whether the DBMS is classified as a single user or multi-user. A
single-user DBMS supports only one user at a time. In other words, if user A is
using the database, user B and C must wait until user A has completed his/her
database work. If a single user database runs on a personal computer, it is
also called a desktop database.
A multiuser DBMS
supports multiple users at the same time. If the multiuser database supports a
relatively small number of users (less than fifty) or a specific department
within an organization, it is called workgroup database. If the database is
used by the entire organization and supports many users across many
departments, the database is known as an enterprise database.
The database site
location might also be used to classify DBMS. For example, DBMS that supports a
database located at a single site is called a centralized DBMS. A DBMS that
supports a database distributed across several different sites is called
distributed DBMS.
The type of computer
systems that database can run can be broken down into four broad categories or
platforms: Centralized, PC, Client/Server and Distributed.
The different
database systems are:
1.
Centralized Database Processing System
2.
Personal Computer System
3.
Client/Server Database System
4.
Distributed Processing Database System
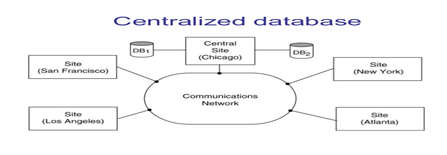
1. Centralized
Database Processing System
In a centralized
system, all programs run on the main host computer, including the DBMS, the
application that accesses the database and the communication facilities that
send and receive data from the user’s terminals. The users access the database
through either locally connected or dial-up (remote) terminals. The terminals
are generally dumb, having little or no processing power of their own and
consists of only a screen, keyboard and hardware to communicate with the host.
2. Personal Computer
Systems
When a DBMS is run on
a PC, the PC acts as both the host computer and the terminal unlike the larger
systems. The DBMS functions and the database application functions are combined
into one application. Database applications on a PC handle the user input,
screen output and access to the data on the disk. Combining these different
functions into one unit gives the DBMS a great deal of power, flexibility and
speed, usually at the cost of decreased data security and integrity.

However, in recent
years many have been connected to a Local Area Networks (LANs). In a LAN, the
data and usually, the user applications reside on the File Server, a PC running
a special Network Operating System (NOS) such as Novell’s NetWare or
Microsoft’s LAN Manager or Windows NT. The file server manages the LAN access
to other shared resources.
3. Client/Server
Database Systems
In a generalized
concept, client PC is the computer from where the user requests for data and
information and the server provides the requested information. The database
application on the client PC referred to as the “front end system” that handles
all the screen and user input/output processing.

The “back end system”
on the database server handles data processing and disk access. For example, a
user on the front end creates a query for data from the database server and the
front-end application sends the request across the network to the server. The
database server performs the actual search and sends back only the data that
answers the user’s query.
4. Distributed
Processing Systems
A simple form of
distributed processing has existed for several years. In this limited form,
data is shared among various host system via updates sent either through direct
connections on the same network or through remote connections via phone or
dedicated data lines.

An application which
runs one or more of the hosts, extracts the portion of data that has been
changed during a programmer-defined period and then transmits the data to
either a centralized host or other hosts in the distributed circuit. The other
databases are then updated so that all the systems are in sync with each other.
This type of
distributed processing usually occurs between departmental computers or LAN's
and host systems; the data goes to a large central minicomputer or mainframe
host after the close of the business day. The below figure illustrates one form
of distributed processing system.

Benefits
of Database Management System
1.
Reduction in data redundancy: In non-database
systems, each application has its own separate files. Each file can have
repeated data in different ways which consume more space. The database
management system removes this problem
2.
Reduction in data inconsistency: The contradictory of
a presence of same data in various forms in the different database can be
removed.
3.
Sharing of data is possible: Same database or
table can be shared with more than one end user during data processing.
4.
Enforcement of standards: In database
management systems, new standards have emerged which can be applied.
5.
Improved in data security: DBMS provides check
and validation rules for the users while accessing databases. This prevents
from piracy of database and data manipulation.
6.
Maintenance of Data Integrity: The data integrity
refers to the accuracy of data. The database management system provides correct
and relevant data records.
7.
Better interaction with end users: The screens and
interfaces for the users have become more friendly in database management
systems.
8.
Efficient systems: The overall efficiency of the database
management system is increased tremendously due to the use of new versions of
database management systems.
Data
security
Data security is one
of the challenging jobs of Database Administrators (DA). The secured data can
be transferred from one server to another server at great distances. For the
prevention of data piracy and data mining, proper securities are necessary to
be implemented in the system. The two common methods of data security are using
the username and password. The username authentication and password verification
can allow for data access. So, data security is a preventive measures that a Database
Administrator (DA) must take for the protection of data from the unauthorized
access, theft, corruption, etc.

{kind=link}
0 Reviews